The Fragmented Landscape of Clinical Data
In today’s healthcare landscape, hospitals generate vast amounts of data daily from numerous sources. This data, typically stored electronically, is spread across different locations within a hospital. For instance, electronic reports detailing patient treatment information are stored within the oncology department, while patient images are housed separately in the radiology department’s Picture Archiving and Communication System (PACS). This segregation extends further, as different departments often employ various infrastructures, utilizing different software and data formats, leading to a lack of interoperability.
Data fragmentation, where data is broken into many pieces that are not adjacent, is a significant issue. This problem escalates in multicenter studies, where data from different institutions must be combined. The lack of standardization across institutions complicates data interoperability, making it challenging to compile relevant information spread across diverse systems.

Types of Data Fragmentation
The primary issue with data fragmentation lies in the scattering of information and the creation of isolated silos. Different departments or teams often establish these silos independently, without considering the broader need for coordination and integration. Data fragmentation is generally categorized into two main types: physical and logical.
Physical fragmentation occurs when data is dispersed across various locations or storage devices. This scattering can make the integration of data a complex and time-consuming task, as it requires retrieving and consolidating information from multiple sources. The technical difficulties involved in this process can further hinder the efficient use of data.
Logical fragmentation, on the other hand, happens when data segments are logically duplicated or divided across different applications or systems. This can result in different versions of the same data being available in various locations. Such fragmentation complicates data management, as it becomes challenging to ensure consistency and accuracy across all versions. Both types of fragmentation pose significant challenges to the seamless use and analysis of clinical data, ultimately impacting the effectiveness of healthcare delivery and research.
The Exponential Growth of Clinical Data
Over the past decade, the use and production of clinical data have surged, particularly in fields like radiation oncology. New technologies, such as advanced scanners that capture images in less than a second, have led to what is termed a ‘data explosion’. While these technological advancements have improved healthcare quality, they have also generated far more data than anticipated. However, the development of data mining techniques has not kept pace with this rapid data growth.

This immense volume of data surpasses human capabilities to manage effectively. Consequently, this largely unexplored data holds tremendous potential for developing clinical prediction models by leveraging comprehensive information from imaging, genetic banks, and electronic reports. Yet, issues like missing values and unstructured data—data lacking a predefined model or organization—pose significant barriers to utilizing this data efficiently.
Understanding the ‘Big’ in Big Clinical Data
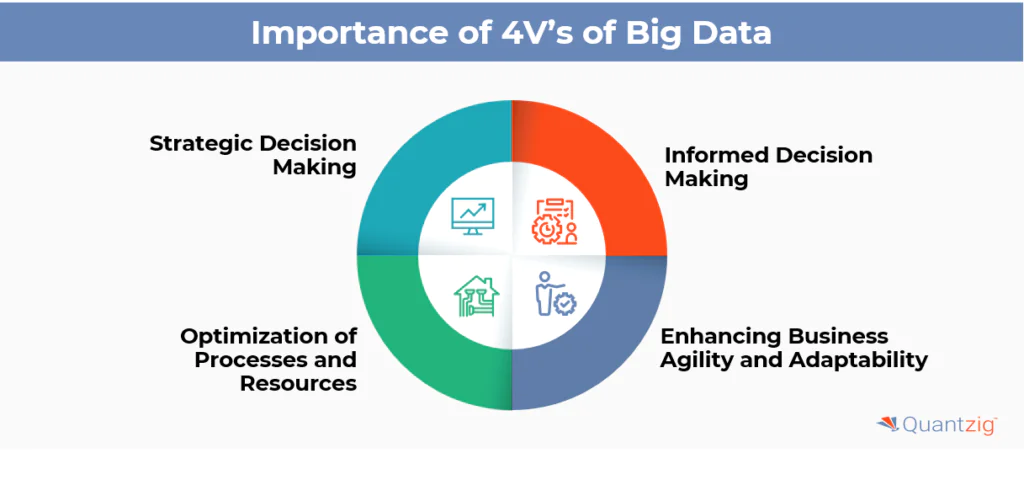
The term big data in the clinical context encompasses not only the sheer volume of data but also its complexity, unstructured nature, and fragmentation. The concept is often distilled into the four ‘Vs’: Volume, Variety, Velocity, and Veracity.

Volume. The amount of data is growing exponentially, driven by both humans and machines. Traditional storage systems struggle to accommodate this vast influx of data.
Variety. Data comes in multiple forms and from various sources, including structured databases, free text, and images. The challenge lies in storing and retrieving this diverse data efficiently and aligning it across different sources.
Velocity. Big data is generated in a continuous and massive flow, requiring real-time analytics. Understanding the temporal dimension of data velocity is crucial, as data’s utility can vary over time.
Veracity. The complexity of big data often results in inconsistencies and noise, making data veracity the most challenging aspect. Accurate representation of data is critical, especially in clinical contexts.
The Expanded Vs: Validity, Volatility, Viscosity, and Virality
In addition to the primary four ‘Vs’—Volume, Variety, Velocity, and Veracity—four more properties have been proposed to further encapsulate the complexities of big clinical data: Validity, Volatility, Viscosity, and Virality
Validity. Ensuring data accuracy for its intended use is crucial, particularly given the sheer volume and veracity challenges inherent in big data. Interestingly, during the initial stages of analysis, it is not always necessary to validate every single data element. Instead, the focus should be on identifying relationships between data elements within the vast dataset. This approach prioritizes the discovery of meaningful patterns and connections over the initial validity of each data point, which can be refined in subsequent analyses.
Volatility. This dimension addresses the lifespan and retention of data. With the ever-increasing capacity demands, it is essential to determine how long data needs to be stored and remain accessible. Volatility reflects the dynamic nature of data utility over time, emphasizing the importance of balancing storage costs with the relevance and necessity of data retention. Understanding when data becomes obsolete helps manage storage efficiently and ensures that only pertinent information is maintained.
Viscosity. Viscosity pertains to the resistance within the data flow, influenced by the complexity and diversity of data sources. High viscosity can result from integration challenges and the friction encountered during data processing. Transforming raw data into actionable insights often requires significant effort, as the diverse origins and formats of big clinical data can hinder smooth and rapid analysis. Overcoming viscosity involves streamlining data integration processes and improving interoperability to facilitate the seamless flow and processing of information.
Virality. Defined as the rate at which data spreads and is reused, virality measures how frequently data is shared and repurposed beyond its original context. In the clinical domain, high virality indicates that data is not only valuable but also widely applicable, benefiting multiple users and applications. Enhancing the virality of clinical data necessitates fostering an environment of open data sharing, where the benefits of broad data access and reuse are recognized and maximized.

Barriers to Big Data Exchange
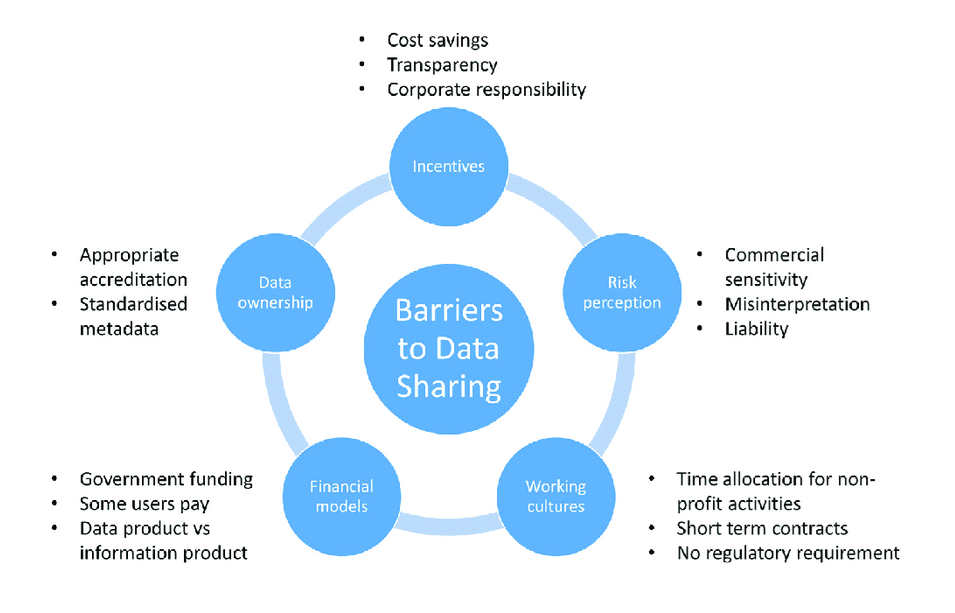
Despite advancements in mining and retrieving meaningful information from big clinical data, several barriers hinder its exchange. First, administrative barriers arise due to the additional efforts and personnel costs required for mining such extensive data. Ethical barriers further complicate the situation, as data privacy concerns and varying privacy laws across different countries create significant challenges. Additionally, political barriers manifest in the reluctance to share data and the need for community-wide cooperation, which often proves difficult to achieve. Lastly, technical barriers pose a major obstacle, with poor data interoperability, lack of standardization, and insufficient support for standardized protocols and formats impeding effective data exchange.
The Path Forward: Standardization and Collaboration
Addressing these challenges necessitates a collaborative effort across the healthcare community. Key steps include accelerating progress toward standardized data models using advanced techniques like ontologies and the Semantic Web. Ontologies provide a common terminology, overcoming language barriers and enabling data and metadata to be queried universally. Furthermore, demonstrating the advantages of using real-world clinical data through high-quality research can highlight the benefits of data exchange, fostering broader acceptance and implementation.
Conclusion
The rapid increase in data volume presents both challenges and opportunities. While big clinical data is characterized by its volume, variety, velocity, and veracity, several barriers limit its effective exchange. Overcoming these barriers through standardization and collaborative efforts is essential for harnessing the full potential of clinical big data, ultimately leading to improved healthcare outcomes.
Engr. Dex Marco Tiu Guibelondo, B.Sc. Pharm, R.Ph., B.Sc. CpE
Subscribe
to get our
LATEST NEWS
Related Posts

Artificial Intelligence and Data Analytics
Sepsis Shadow: Machine-Learning Risk Mapping for Stroke Patients with Bloodstream Infection
Regularized models like LASSO can identify an interpretable risk signature for stroke patients with bloodstream infection, enabling targeted, physiology-aligned clinical management.

Artificial Intelligence and Data Analytics
Agentic Divide: Disentangling AI Agents and Agentic AI Across Architecture, Application, and Risk
The distinction between AI Agents and Agentic AI defines the boundary between automation and emergent system-level intelligence.


Read More Articles




Medicinal Chemistry & Pharmacology
February 16, 2026
Spatial Collapse: Pharmacologic Degradation of PDEδ to Disrupt Oncogenic KRAS Membrane Localization
PDEδ degradation disrupts KRAS membrane localization to collapse oncogenic signaling through spatial pharmacology rather than direct enzymatic inhibition.

Medicinal Chemistry & Pharmacology
February 4, 2026
Neumedics’ Integrated Innovation Model: Dr. Mark Nelson on Translating Drug Discovery into API Synthesis
Dr. Mark Nelson of Neumedics outlines how integrating medicinal chemistry with scalable API synthesis from the earliest design stages defines the next evolution of pharmaceutical development.

Clinical Operations
February 3, 2026
Zentalis Pharmaceuticals’ Clinical Strategy Architecture: Dr. Stalder on Data Foresight and Oncology Execution
Dr. Joseph Stalder of Zentalis Pharmaceuticals examines how predictive data integration and disciplined program governance are redefining the future of late-stage oncology development.

Medicinal Chemistry & Pharmacology
February 2, 2026
Exelixis Clinical Bioanalysis Leadership, Translational DMPK Craft, and the Kirkovsky Playbook
Senior Director Dr. Leo Kirkovsky brings a rare cross-modality perspective—spanning physical organic chemistry, clinical assay leadership, and ADC bioanalysis—to show how ADME mastery becomes the decision engine that turns complex drug systems into scalable oncology development programs.

Regulatory Affairs
January 30, 2026
Policy Ignition: How Institutional Experiments Become Durable Global Evidence for Pharmaceutical Access
Global pharmaceutical access improves when IP, payment, and real-world evidence systems are engineered as interoperable feedback loops rather than isolated reforms.